GRUB Parameters for GPU Passthrough: A Comprehensive Guide

1. Introduction
1.1 Purpose and Scope
GRUB parameters play a fundamental role in successful GPU passthrough, acting as the initial gatekeepers that prepare your system for this advanced virtualization technique. Think of these parameters as a set of specific instructions given to your computer at its earliest boot stage - before even the operating system starts. They're crucial because they establish the groundwork for how your system will handle and isolate hardware components, particularly your graphics card.
In this guide, we'll explore these essential boot parameters in detail, understanding not just what they do, but why they're necessary for GPU passthrough. GRUB parameters configure critical systems like the IOMMU (Input-Output Memory Management Unit), which creates the hardware isolation needed for passthrough. Without proper GRUB configuration, your GPU passthrough setup simply won't work, as the system won't be prepared to properly separate and manage your graphics card for virtual machine use.
Consider GRUB parameters as the foundation of a building - while they're not the entire structure, everything else depends on them being correctly set. This guide focuses specifically on identifying, understanding, and implementing the right GRUB parameters for your specific hardware configuration, ensuring you have this crucial foundation properly in place.
1.2 Target Audience
This guide serves several distinct groups of users:
Primary Audiences
Linux users following our main GPU passthrough guide who need deeper understanding of the GRUB configuration process. If you're working through setting up GPU passthrough for the first time, this guide serves as your detailed reference for one of the most crucial early steps.
System administrators and technical users who are already familiar with virtualization concepts will find this guide valuable for understanding the specific intricacies of GRUB parameters in the context of GPU passthrough. While you may already be comfortable with GRUB configuration, the unique requirements of GPU passthrough introduce additional complexity that this guide thoroughly addresses.
Secondary Audiences
Troubleshooters who have attempted GPU passthrough but encountered issues related to GRUB configuration. If you're experiencing problems with IOMMU grouping, graphics card initialization, or other boot-time issues, this guide will help you understand and resolve these challenges.
Required Background
This guide assumes you have:
- Basic familiarity with Linux system administration concepts
- Comfort using the command line
- Understanding of basic virtualization principles
If you're entirely new to Linux or system administration, we recommend first reviewing our introductory guides to Linux system management and virtualization basics before diving into this more specialized topic.
[These guides are yet to be created :) but will be available in the future]
1.3 Prerequisites and Assumptions
For this guide to be most effective, there are several technical prerequisites and assumptions we should establish. Understanding these requirements upfront will help ensure you can successfully implement and troubleshoot GRUB parameters for GPU passthrough.
Hardware Prerequisites
Your system must have:
- A CPU with virtualization support (Intel VT-d or AMD-Vi)
- A motherboard that supports IOMMU grouping
- At least one GPU for passthrough (in our examples, we'll reference the NVIDIA RTX 3090)
- Sufficient system RAM to support both host and guest systems
In our specific examples, we'll be referencing a system configuration using:
- Intel i7-11700K processor
- MSI MAG Z590 Torpedo Motherboard
- NVIDIA RTX 3090 Graphics Card
- 32GB DDR4 RAM
Software Prerequisites
Your system should have:
- A Linux distribution with a kernel version 5.10 or newer
- GRUB2 bootloader installed and configured as your primary bootloader
- Basic system utilities for hardware inspection (lspci, dmesg, etc.)
- Root access or sudo privileges for system configuration
Knowledge Prerequisites
We assume you understand:
- Basic Linux file system navigation
- How to use a command-line text editor (vim, nano, etc.)
- Basic concepts of system booting and bootloaders
- Fundamental virtualization concepts
Important Assumptions
This guide assumes:
- You're using GRUB as your bootloader
- Your system uses UEFI boot (though we'll briefly cover legacy boot considerations)
- You have physical access to the system in case of boot issues
- You can perform system backups before making changes
- You're familiar with basic troubleshooting procedures
What This Guide Doesn't Cover
To maintain focus, we won't cover:
- Basic Linux installation and setup
- Virtual machine creation and configuration
- General system administration tasks
- Non-GRUB bootloader configurations
1.4 Technical Background Needed
Understanding GRUB parameters for GPU passthrough requires familiarity with several fundamental technical concepts. Let's establish this crucial background knowledge before diving into the specific parameters and their implementation.
Boot Process Understanding
The computer boot process follows a specific sequence, and GRUB plays a pivotal role in this sequence. When you power on your system, it goes through these stages:
- The firmware (UEFI/BIOS) initializes essential hardware
- GRUB takes control and loads its configuration
- GRUB then loads the Linux kernel with specified parameters
- The kernel initializes hardware according to these parameters
- The system continues its regular boot process
Understanding this sequence is crucial because GRUB parameters influence how the kernel will initialize and manage hardware throughout your system's operation. It's like setting rules for a game before it begins - these rules can't be easily changed once play has started.
Hardware Initialization Concepts
Your system's hardware doesn't simply "turn on" - it goes through a complex initialization process. During this process, the system:
- Identifies available hardware components
- Allocates system resources (memory regions, I/O ports)
- Sets up communication channels between components
- Loads and initializes appropriate drivers
GRUB parameters can influence each of these steps, particularly for complex components like GPUs and their associated subsystems.
IOMMU Fundamentals
The Input-Output Memory Management Unit (IOMMU) is a critical component for GPU passthrough. Think of it as a traffic controller for your system's hardware components. The IOMMU:
- Creates isolated "zones" for different hardware components
- Manages direct memory access (DMA) operations
- Prevents devices from interfering with each other
- Enables safe device assignment to virtual machines
Without proper IOMMU configuration through GRUB parameters, GPU passthrough becomes either impossible or potentially unsafe.
PCIe Bus Architecture
Your graphics card communicates with the system through the PCIe (PCI Express) bus. Understanding basic PCIe concepts helps explain why certain GRUB parameters are necessary:
- PCIe uses a hierarchical structure
- Devices are grouped into IOMMU groups based on their PCIe topology
- Some devices share resources and can't be separated
- The motherboard's PCIe layout affects passthrough possibilities
Driver and Kernel Interaction
Graphics cards require specific drivers to function. During the boot process:
- The kernel loads initial graphics drivers
- GRUB parameters can influence which drivers load
- Some drivers must be specifically prevented from binding to cards intended for passthrough
- The timing of driver initialization matters for successful passthrough
2. Quick Start Guide for Experienced Users

2.1 Essential Parameters Overview
For experienced system administrators who need to quickly implement GPU passthrough, here's a streamlined set of GRUB parameters. Think of this as your "quick reference card" - we'll explore each parameter in detail later in the guide, but this gives you the essential configuration to get started.
For an Intel-based system with an NVIDIA GPU (like our example RTX 3090 setup), here's the minimal required configuration:
bash
GRUB_CMDLINE_LINUX_DEFAULT="intel_iommu=on iommu=pt rd.driver.pre=vfio-pci pcie_acs_override=downstream,multifunction"
For an AMD-based system with the same GPU:
bash
GRUB_CMDLINE_LINUX_DEFAULT="amd_iommu=on iommu=pt rd.driver.pre=vfio-pci pcie_acs_override=downstream,multifunction"
Adding these parameters provides the fundamental requirements for GPU passthrough:
- Enables IOMMU support
- Configures IOMMU for passthrough mode
- Preloads VFIO drivers
- Handles ACS override for proper device isolation
2.2 Basic Implementation Steps
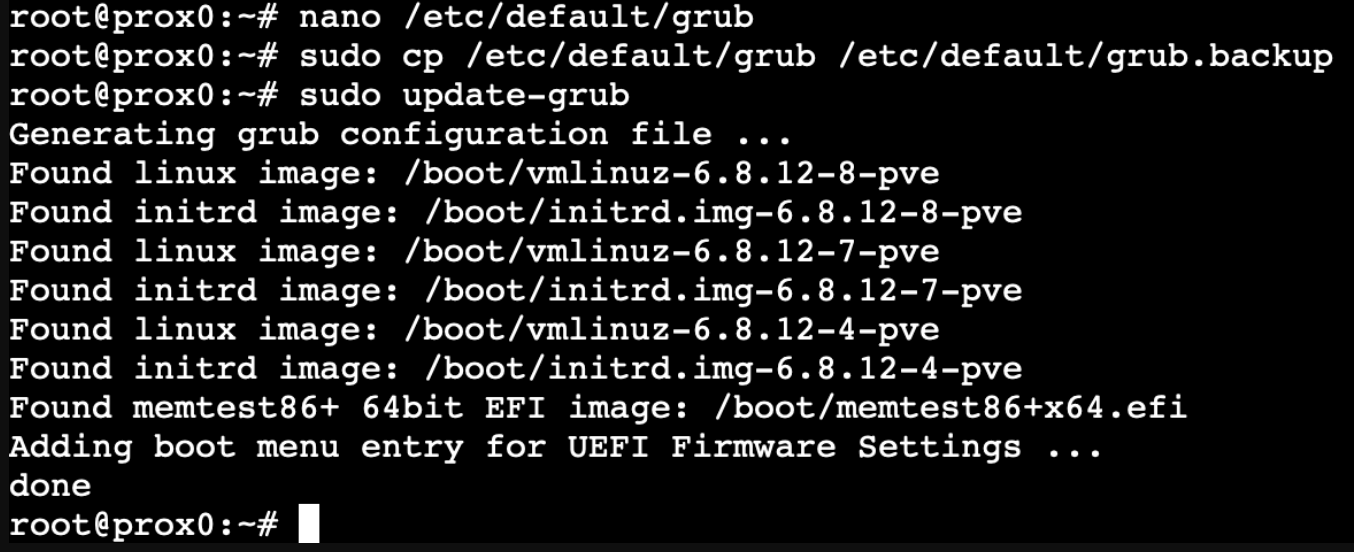
- Back up your current GRUB configuration:
bash
sudo cp /etc/default/grub /etc/default/grub.backup
- Edit your GRUB configuration:
bash
sudo nano /etc/default/grub
- Add the parameters to the
GRUB_CMDLINE_LINUX_DEFAULTline - Update GRUB:
bash
# For most distributions:
sudo update-grub
# For some distributions like CentOS:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
- Reboot your system to apply changes
Example:

2.3 Quick Verification
After reboot, verify IOMMU is working:
bash
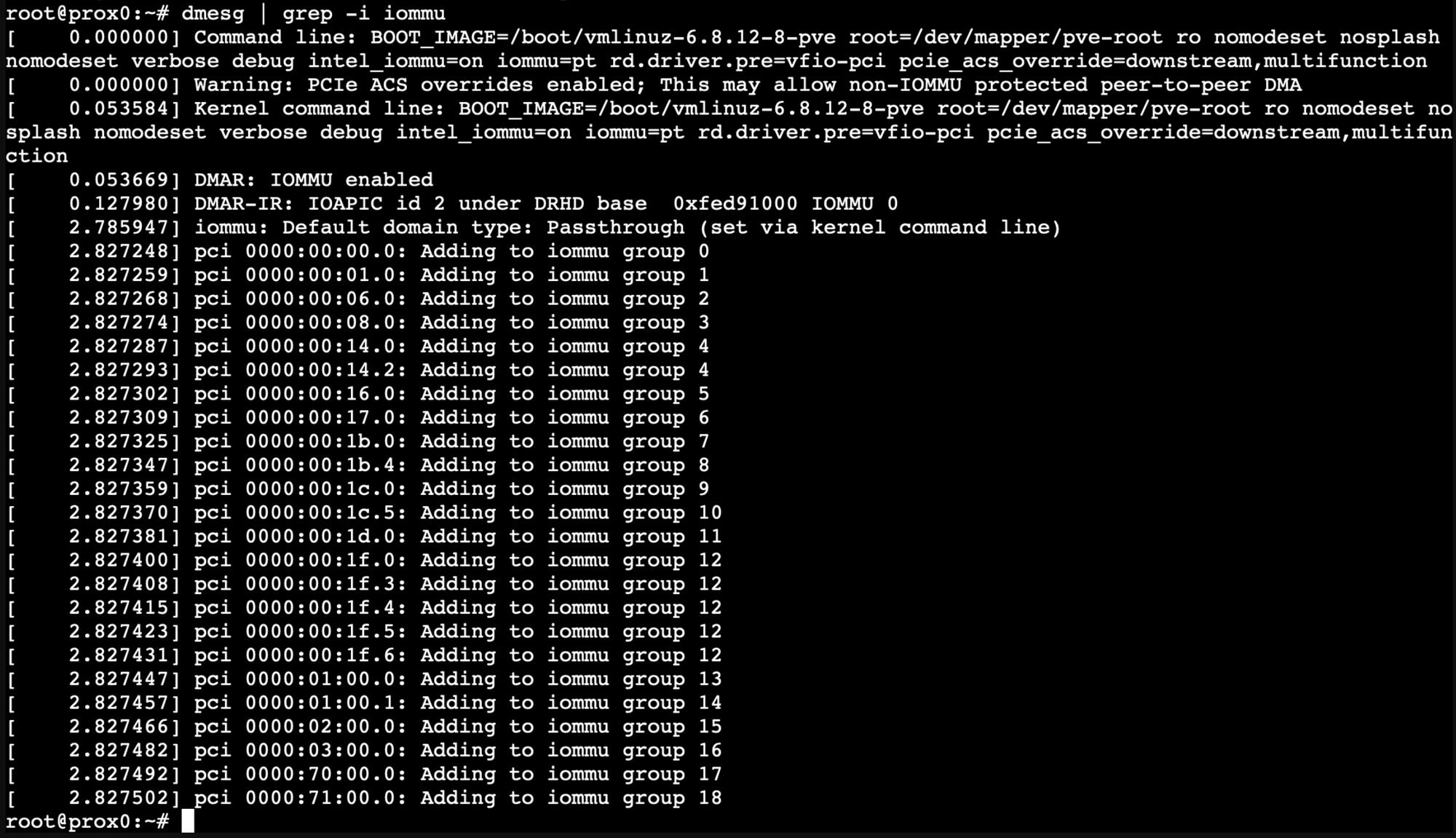
# Check if IOMMU is enabled
dmesg | grep -i iommu
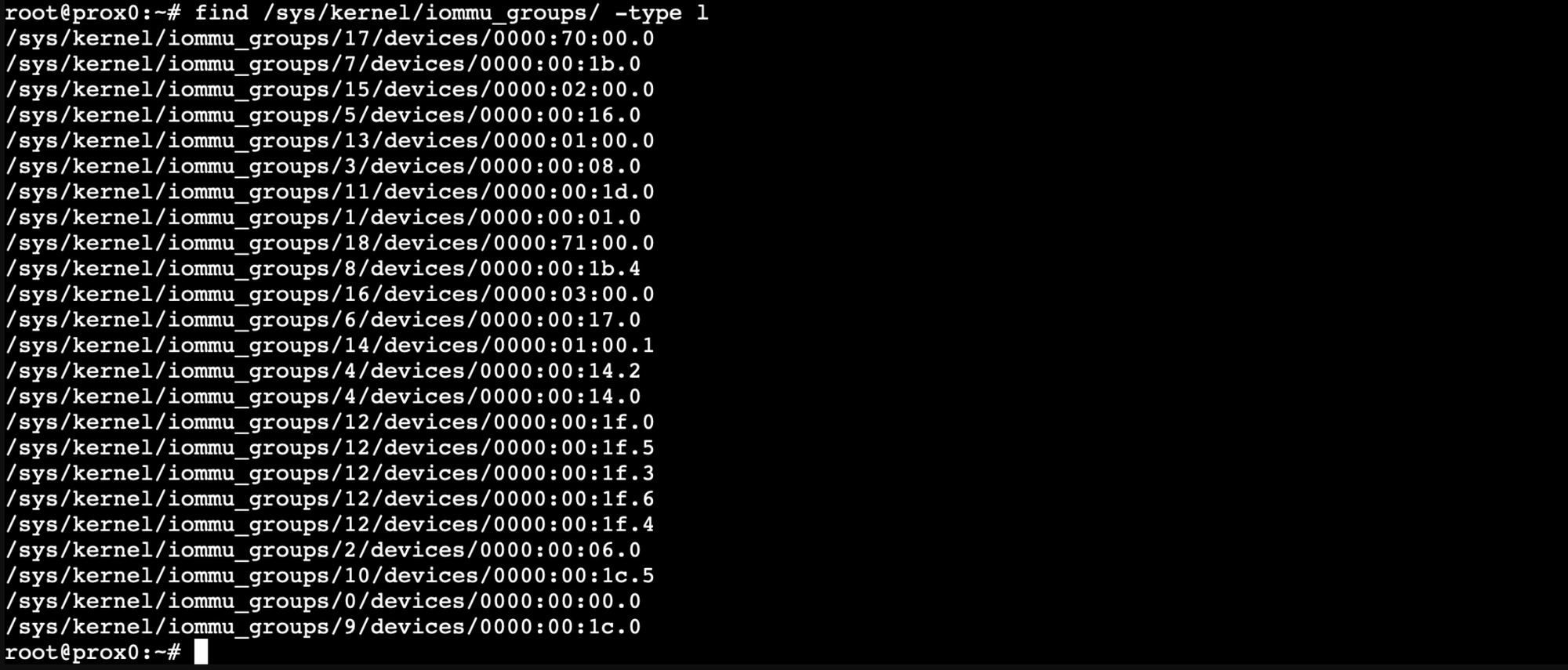
# Verify your GPU's IOMMU group
find /sys/kernel/iommu_groups/ -type l
You should see your GPU listed in an IOMMU group, and the dmesg output should show IOMMU initialization messages.
2.4 When to Read the Full Guide
While this quick start gets you running, you should read the full guide if:
- Your hardware has special requirements
- You encounter boot or stability issues
- You need to optimize performance
- You want to understand the security implications
- You're setting up a production environment
Remember: This quick start uses a relatively permissive configuration. For production environments, you'll want to review the security considerations in the main guide sections.
3. Understanding GRUB's Role in GPU Passthrough

3.1 The Boot Process and GRUB's Function
The boot process of a computer is like a carefully orchestrated symphony, with each component playing its part at precisely the right moment. GRUB serves as the conductor of this symphony, directing how your system comes to life and preparing it for GPU passthrough.
When you press your computer's power button, a sequence of events unfolds:
- First, your system's firmware (UEFI or BIOS) performs its Power-On Self-Test (POST) and initializes the basic hardware.
- Then, control passes to GRUB, which resides in a special partition on your drive. This moment is crucial because GRUB has a unique position in the boot process - it runs before your operating system starts, making it the perfect place to set up special hardware configurations.
- GRUB reads its configuration file, which contains the parameters we'll be setting. These parameters are like instructions passed to the orchestra members (in our case, the Linux kernel) before the performance begins.
- Finally, GRUB loads the Linux kernel into memory and passes along our special parameters. The kernel then uses these parameters to determine how to initialize and manage the hardware throughout the system's operation.
For GPU passthrough, this sequence is particularly important because certain decisions about hardware management must be made very early in the boot process. It's like setting up a room divider - it's much easier to place it before people enter the room than to try to reorganize everything after the room is full.
Consider this real-world example using our test system (Intel i7-11700K with RTX 3090):
bash
# Normal boot without GPU passthrough parameters
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
In the first case, the system boots normally, treating all hardware as generally accessible.
# Boot with GPU passthrough parameters
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash intel_iommu=on iommu=pt"
In the second case, GRUB tells the kernel to enable Intel's IOMMU technology and prepare for PCI passthrough from the very beginning of the boot process.
3.2 Hardware Initialization Sequence
Imagine building a complex LEGO structure. Just as you need to lay certain foundational pieces before adding the more complex parts, your system needs to initialize hardware in a specific order. GRUB's parameters help define this initialization sequence, particularly for GPU passthrough.
The sequence typically flows like this:
- CPU and Memory Initialization
- GRUB parameters can affect how memory regions are allocated
- IOMMU settings establish memory management boundaries
- PCI Bus Enumeration
- The system discovers and catalogs PCI devices
- GRUB parameters influence how devices are grouped and isolated
- Device Driver Loading
- The kernel decides which drivers to load for each device
- Our parameters can prevent certain drivers from claiming the GPU we want to pass through
Using our RTX 3090 as an example, proper initialization requires preventing the standard NVIDIA driver from claiming the card so that the VFIO driver can manage it instead. This is achieved through specific GRUB parameters that we'll explore in detail later.
3.3 GRUB's Relationship with Kernel and Hardware
The relationship between GRUB, the Linux kernel, and your hardware is like a carefully planned relay race. Each participant needs to hand off information and control at precisely the right moment, with GRUB serving as both the starting official and the first runner in this race.
The Communication Chain
When GRUB hands control to the kernel, it doesn't simply step aside. Instead, it passes along a set of crucial instructions (our parameters) that influence how the kernel will manage hardware throughout the entire system's operation. This is particularly important for GPU passthrough because these initial instructions establish the groundwork for hardware isolation.
Using our test system with an Intel i7-11700K and RTX 3090, here's the production-ready GRUB configuration:
bash
# Production-ready GRUB configuration for GPU passthrough
GRUB_CMDLINE_LINUX_DEFAULT="nosplash nomodeset verbose debug intel_iommu=on iommu=pt rd.driver.pre=vfio-pci pcie_acs_override=downstream,multifunction"
Let's understand each parameter and its crucial role:
nosplash nomodeset: These parameters prevent the host system from trying to use the GPU during boot. Thenomodesetparameter is particularly crucial as it stops the kernel from loading video drivers that might interfere with passthrough.verbose debug: These enable detailed boot logging, which is essential for troubleshooting any issues that might arise during the passthrough setup or after kernel updates.intel_iommu=on: Enables Intel's IOMMU technology (useamd_iommu=onfor AMD processors). This is fundamental for device isolation.iommu=pt: Optimizes the IOMMU specifically for PCI passthrough operations, improving performance and reliability.rd.driver.pre=vfio-pci: Ensures the VFIO driver loads early in the boot process, before other drivers can claim our GPU.pcie_acs_override=downstream,multifunction: Helps ensure proper PCIe device isolation, particularly important for systems where IOMMU grouping isn't ideal.
On our test system, these parameters result in the following IOMMU grouping:
bash
IOMMU Group 13 01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GA102 [GeForce RTX 3090] [10de:2204] (rev a1)
Hardware Management Flow
Think of this process like setting up a complex stage production. Each component needs to be in place and properly configured before the show can begin. With our production-ready GRUB configuration, here's how the sequence unfolds:
- GRUB sets the initial conditions by passing our carefully chosen parameters to the kernel. The
nosplashandnomodesetparameters ensure we can see what's happening during this crucial setup phase. - Thanks to the
verboseanddebugparameters, the kernel provides detailed information as it reads and implements these parameters during its earliest initialization phase. This transparency is invaluable for catching any issues early. - The
intel_iommu=onandiommu=ptparameters enable and configure the IOMMU hardware. At this stage, the system is establishing the secure boundaries that will keep our RTX 3090 isolated for passthrough. - Because we specified
rd.driver.pre=vfio-pci, the VFIO driver loads before any other GPU drivers can claim our RTX 3090. This early preparation is crucial for clean device isolation. - Finally,
pcie_acs_override=downstream,multifunctionensures proper PCIe device separation, preventing any unwanted resource sharing that could interfere with passthrough performance.
3.4 Visual Diagram of the Boot Process
Let me explain the boot sequence visually, showing where GRUB parameters influence GPU passthrough:
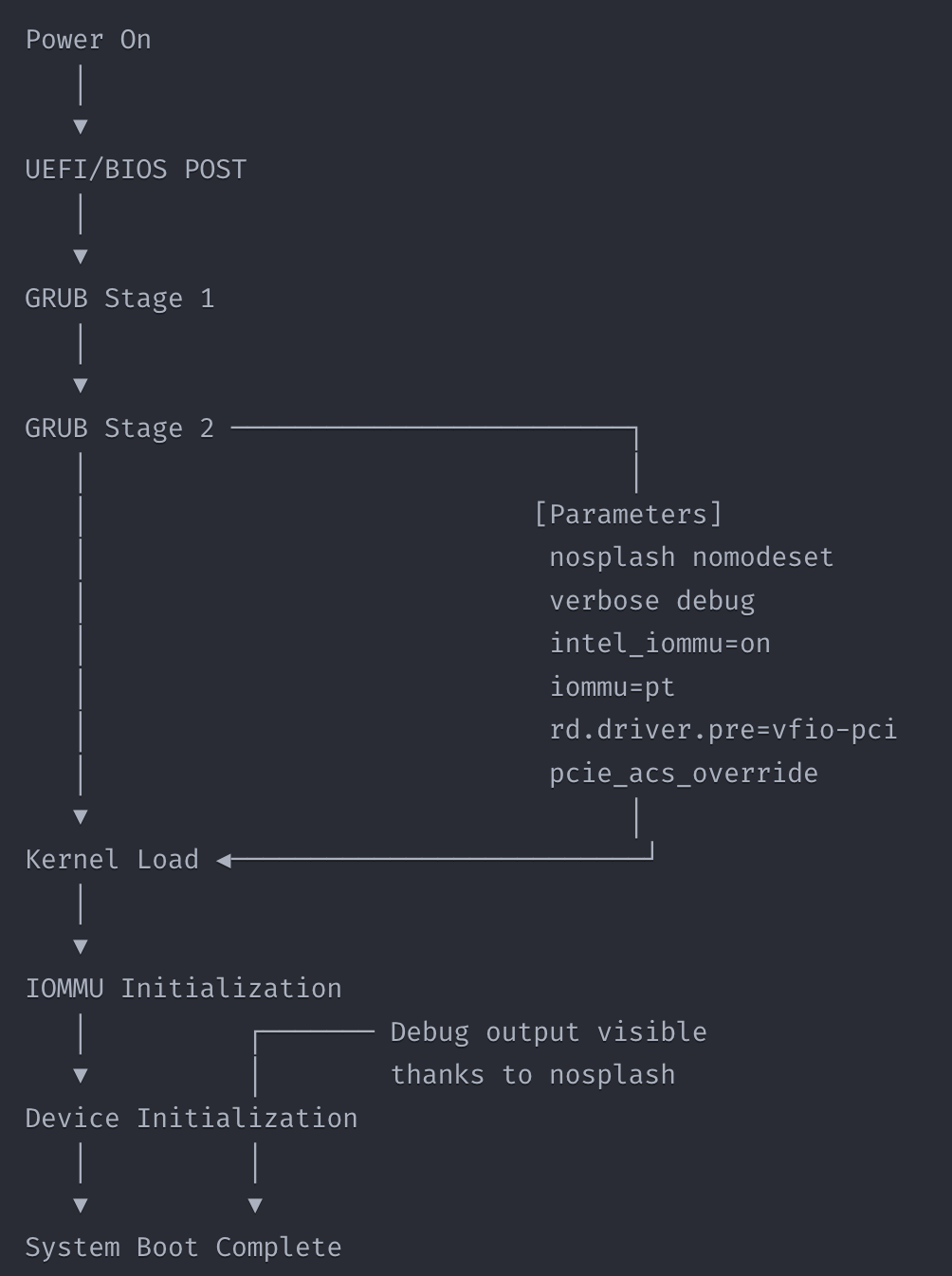
3.5 Why GRUB Configuration Matters for Passthrough
The importance of proper GRUB configuration for GPU passthrough cannot be overstated. It's like constructing a high-security facility – every security measure must be in place before operations begin, as adding them later is nearly impossible.
Consider these key aspects:
- Early Hardware Assignment: Our configuration ensures the IOMMU is enabled and VFIO drivers are loaded before any other drivers can claim our RTX 3090. The
nomodesetparameter provides additional protection by preventing the host system from trying to use the GPU for display purposes. Without these early preparations, the GPU might be claimed by the standard NVIDIA driver, making passthrough impossible. - Resource Isolation: The combination of
intel_iommu=on,iommu=pt, andpcie_acs_overrideparameters creates a robust isolation framework. This is like having proper security clearances and separate secure areas in our facility – each component only has access to the resources it should have, preventing any unintended interactions. - Performance Optimization: Parameters like
iommu=ptoptimize the IOMMU specifically for PCI passthrough. For a high-performance card like the RTX 3090, this ensures we're providing the best possible environment for maximum performance in the virtual machine. - Troubleshooting Capability: The
verboseanddebugparameters, combined withnosplash, give us visibility into the boot process. If something goes wrong, we have the diagnostic information needed to identify and resolve the issue quickly.
3.6 Common Misconceptions and Pitfalls
When setting up GPU passthrough, several misconceptions can lead users down problematic paths. Understanding these potential issues helps ensure a successful implementation.
Misconception 1: "I can modify GRUB parameters after system setup"
While you can technically change GRUB parameters at any time, making changes after your system is fully configured can lead to unexpected complications. Think of it like trying to change the foundation of a house after it's built – technically possible, but fraught with risk.
For example, if you initially set up your system without IOMMU enabled and later add intel_iommu=on, you might find that your system's device assignments have already been established in ways that make clean GPU passthrough difficult. Applications and services might be using device paths that will change when IOMMU grouping is enabled.
Misconception 2: "Default IOMMU settings are good enough"
Many users assume that simply enabling IOMMU with intel_iommu=on is sufficient. However, on our test system with the RTX 3090, we found that additional parameters like iommu=pt and pcie_acs_override are crucial for optimal performance and proper device isolation. The default IOMMU settings prioritize compatibility over the strict isolation needed for GPU passthrough.
Consider this real-world example:
bash
# Insufficient configuration
GRUB_CMDLINE_LINUX_DEFAULT="intel_iommu=on"
# Proper production configuration
GRUB_CMDLINE_LINUX_DEFAULT="nosplash nomodeset verbose debug intel_iommu=on iommu=pt rd.driver.pre=vfio-pci pcie_acs_override=downstream,multifunction"
Misconception 3: "Kernel updates won't affect my GRUB configuration"
A common pitfall is assuming that once GRUB is configured correctly, it will stay that way through system updates. However, kernel updates can sometimes modify GRUB configuration files. This is why it's crucial to:
- Always keep a backup of your working GRUB configuration
- Verify your GRUB parameters after kernel updates
- Consider setting up automated configuration management (which we'll cover in later sections)
Misconception 4: "More GRUB parameters always mean better isolation"
Some users add every GRUB parameter they find mentioned in various guides. This "kitchen sink" approach can actually create problems. For example, adding unnecessary ACS override options might weaken the natural isolation boundaries your hardware provides. Stick to the proven parameters we've outlined unless you have a specific reason to add others.
Misconception 5: "Debug parameters aren't necessary in production"
Many users skip parameters like verbose and debug, considering them unnecessary in a production environment. However, these parameters are valuable even in stable setups because they:
- Help identify issues quickly when they arise
- Provide crucial information after kernel updates
- Assist in diagnosing performance problems
- Make remote troubleshooting possible
Critical Pitfalls to Avoid
- Not Backing Up Configurations Always make a backup before modifying GRUB:bashCopy
sudo cp /etc/default/grub /etc/default/grub.backup - Ignoring Boot Messages The
nosplashparameter exists for a reason. Boot messages can provide early warning of configuration issues before they become serious problems. - Incomplete Parameter Sets Each parameter in our recommended configuration serves a specific purpose. Omitting any of them might lead to subtle issues that are hard to diagnose later.
By understanding these common misconceptions and pitfalls, you can avoid many of the common problems that users encounter when setting up GPU passthrough.
4. Parameter Selection Framework
4.1 Understanding Parameter Requirements
Before we begin configuring GRUB, we need to understand exactly what each parameter does and why we need it. Think of these parameters as building blocks - each one serves a specific purpose in creating our GPU passthrough foundation.
Let's examine each parameter using our test system
(Intel i7-11700K with RTX 3090) as a practical example:
bash
GRUB_CMDLINE_LINUX_DEFAULT="nosplash nomodeset verbose debug intel_iommu=on iommu=pt rd.driver.pre=vfio-pci pcie_acs_override=downstream,multifunction"
Display and Debug Parameters
bashnosplash nomodeset verbose debug
These parameters control how our system boots and provides diagnostic information:
nosplash: Disables the boot splash screen, allowing us to see boot messagesnomodeset: Prevents the kernel from loading video drivers early in the boot processverbose debug: Provides detailed boot information for troubleshooting
IOMMU Configuration Parameters
bashintel_iommu=on iommu=pt
These parameters enable and configure IOMMU:
intel_iommu=on: Activates Intel's IOMMU technology (useamd_iommu=onfor AMD processors)iommu=pt: Optimizes IOMMU for PCI passthrough operations
Driver Management Parameters
bashrd.driver.pre=vfio-pci
This parameter ensures proper driver loading:
- Loads the VFIO driver before other drivers can claim our GPU
PCIe Configuration Parameters
bashpcie_acs_override=downstream,multifunction
This parameter helps with device isolation:
- Enables proper IOMMU grouping on consumer hardware
- Allows for clean GPU passthrough on motherboards without native ACS support
4.2 Creating a Documented Configuration
When implementing these parameters, we should maintain a well-documented configuration that explains our choices. Let's create this in /etc/default/grub:
bash
# First, create a backup of our current configuration
cp /etc/default/grub "/etc/default/grub.backup.$(date +%Y%m%d)"
now edit the GRUB configurationnano /etc/default/grub
Add our configuration with proper documentation:
bash
# GPU Passthrough Configuration
# Last updated: $(date +%Y-%m-%d)
# Hardware: Intel i7-11700K, RTX 3090, MSI MAG Z590 Torpedo
#
# Parameter explanations:
# nosplash nomodeset - Prevent host GPU initialization
# verbose debug - Enable detailed boot logging
# intel_iommu=on - Enable Intel IOMMU support
# iommu=pt - Optimize IOMMU for PCI passthrough
# rd.driver.pre=vfio-pci - Ensure VFIO driver loads first
# pcie_acs_override=downstream,multifunction - Enable proper IOMMU grouping
#
GRUB_CMDLINE_LINUX_DEFAULT="nosplash nomodeset verbose debug intel_iommu=on iommu=pt rd.driver.pre=vfio-pci pcie_acs_override=downstream,multifunction"
After saving this configuration, we apply it and create our initial verification log:
Apply the configuration
bashupdate-grub
Create our configuration log
echo "# GPU Passthrough Configuration Log" > /root/gpu-passthrough-config.log
echo "Initial configuration: $(date)" >> /root/gpu-passthrough-config.log
echo "Kernel version: $(uname -r)" >> /root/gpu-passthrough-config.log
echo "Current parameters:" >> /root/gpu-passthrough-config.log
cat /proc/cmdline >> /root/gpu-passthrough-config.log
4.3 Verifying Our Configuration
After applying our GRUB parameters, we need to systematically verify that each component is working as intended. This verification process serves two purposes: it confirms our current setup works correctly, and it establishes a baseline for future comparisons.
Initial Parameter Verification
First, let's verify that our parameters were properly applied. When we check the kernel command line, we should see our exact parameters in use:
bashcat /proc/cmdline
On our test system, this shows:
BOOT_IMAGE=/boot/vmlinuz-6.8.12-8-pve root=/dev/mapper/pve-root ro nosplash nomodeset verbose debug intel_iommu=on iommu=pt rd.driver.pre=vfio-pci pcie_acs_override=downstream,multifunction
Understanding this output is crucial. The beginning part (BOOT_IMAGE= and root=) is standard system information, while everything after that represents our custom parameters. Each parameter appears exactly as we configured it, indicating that GRUB successfully passed them to the kernel.
IOMMU Configuration Check
Next, we verify that the IOMMU is properly enabled and configured. The kernel messages will tell us if our IOMMU parameters are working:
bashdmesg | grep -i "iommu"
In a properly configured system, we see:
[ 0.053669] DMAR: IOMMU enabled
[ 2.785947] iommu: Default domain type: Passthrough (set via kernel command line)
These messages confirm two critical things:
- The IOMMU hardware initialized successfully (
DMAR: IOMMU enabled) - The passthrough mode is active (
Default domain type: Passthrough)
GPU Isolation Verification
Perhaps the most critical verification is checking our GPU's IOMMU group isolation. A properly isolated GPU means it's ready for passthrough:
bashls -l /sys/kernel/iommu_groups/13/devices/
On our test system, we see:
total 0
lrwxrwxrwx 1 root root 0 Feb 1 18:41 0000:01:00.0 -> ../../../../devices/pci0000:00/0000:00:01.0/0000:01:00.0
This output tells us something important: our RTX 3090 (device 0000:01:00.0) is alone in its IOMMU group. This isolation is exactly what we need for reliable GPU passthrough.
Driver Status Check
Finally, we verify that no host system drivers have claimed our GPU:
bashlspci -nnk -d 10de:2204
The ideal output shows:
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GA102 [GeForce RTX 3090] [10de:2204] (rev a1)
Subsystem: ASUSTeK Computer Inc. GA102 [GeForce RTX 3090] [1043:87d9]
Kernel modules: nvidiafb, nouveau
Notice there's no "Kernel driver in use" line - this means our GPU is ready for passthrough. The system knows about possible drivers (nvidiafb, nouveau) but isn't using them, exactly as we want.
Documentation for Future Reference
Let's document these verification results in our configuration log. This creates a known-good reference point:
bash
echo "=== Verification Results $(date) ===" >> /root/gpu-passthrough-config.log
echo "IOMMU Status:" >> /root/gpu-passthrough-config.log
dmesg | grep -i "iommu" >> /root/gpu-passthrough-config.log
echo "GPU IOMMU Group:" >> /root/gpu-passthrough-config.log
ls -l /sys/kernel/iommu_groups/13/devices/ >> /root/gpu-passthrough-config.log
echo "GPU Driver Status:" >> /root/gpu-passthrough-config.log
lspci -nnk -d 10de:2204 >> /root/gpu-passthrough-config.log
This documentation serves as our baseline - a snapshot of a working configuration that we can refer back to if issues arise after system updates or changes.
4.4 Bridging Configuration and Maintenance
Now that we have a working configuration and have verified each component, we need to understand how this setup fits into our long-term system maintenance strategy. Think of this like establishing a maintenance schedule for a high-performance car - we need regular checks and a clear understanding of what to watch for.
Understanding Configuration Dependencies
Our GPU passthrough configuration depends on several system components working together:
When the system boots, it follows a specific sequence:
- GRUB reads our configuration from
/etc/default/grub - These parameters are passed to the Linux kernel
- The kernel initializes hardware according to our parameters
- Various subsystems (IOMMU, PCIe, drivers) configure themselves based on these parameters
This sequence can be affected by system updates in several ways:
- Kernel updates might introduce new default behaviors
- GRUB updates could modify how parameters are handled
- System updates might change how drivers are loaded
- Hardware firmware updates could affect IOMMU grouping
Creating a Maintenance Strategy
Understanding these dependencies helps us create an effective maintenance strategy. Let's establish a systematic approach to managing our configuration:
bash
# First, create a baseline record of our working configuration
echo "=== Configuration Baseline $(date) ===" >> /root/gpu-passthrough-config.log
echo "System Information:" >> /root/gpu-passthrough-config.log
echo "Kernel: $(uname -r)" >> /root/gpu-passthrough-config.log
echo "GRUB Version: $(grub-install --version)" >> /root/gpu-passthrough-config.log
# Save our complete GRUB configuration
echo "GRUB Configuration:" >> /root/gpu-passthrough-config.log
cat /etc/default/grub >> /root/gpu-passthrough-config.log
# Document working hardware state
echo "Hardware State:" >> /root/gpu-passthrough-config.log
lspci -nnk >> /root/gpu-passthrough-config.log
This baseline serves as our reference point. When system updates occur, we can compare the current state against this baseline to identify any changes that might affect our GPU passthrough setup.
Preparing for System Updates
Before we dive into specific update procedures, let's establish some key principles for maintaining our configuration:
- Documentation is crucial. Every change to our system should be logged:
# Create an update log entry
log_update() {
echo "=== Update Event $(date) ===" >> /root/gpu-passthrough-config.log
echo "Previous kernel: $(uname -r)" >> /root/gpu-passthrough-config.log
echo "Previous GRUB config:" >> /root/gpu-passthrough-config.log
cat /etc/default/grub >> /root/gpu-passthrough-config.log
}
- Verification should be systematic. We need to check each component of our configuration:
# Create a verification function
verify_passthrough() {
echo "=== Verification $(date) ===" >> /root/gpu-passthrough-config.log
echo "Current kernel: $(uname -r)" >> /root/gpu-passthrough-config.log
echo "IOMMU Status:" >> /root/gpu-passthrough-config.log
dmesg | grep -i "iommu" >> /root/gpu-passthrough-config.log
echo "GPU Status:" >> /root/gpu-passthrough-config.log
lspci -nnk -d 10de:2204 >> /root/gpu-passthrough-config.log
}
- Backups should be consistent and easily identifiable:
# Create a backup function
backup_grub() {
local backup_file="/etc/default/grub.backup.$(date +%Y%m%d)"
cp /etc/default/grub "$backup_file"
echo "Backup created: $backup_file" >> /root/gpu-passthrough-config.log
}
These tools and principles form the foundation of our maintenance strategy. They help ensure that our GPU passthrough configuration remains stable and functional even as the system evolves through updates and changes.
The functions (log_update, backup_grub, and verify_passthrough) need to be properly defined before we can use them. Think of these functions like specialized tools - we need to create them before we can use them.
Let's create these tools properly by adding them to a dedicated script file. This is more robust than adding them to .bash_aliases since it keeps our GPU passthrough maintenance tools organized in one place.
First, let's create a new script file:
bashnano /root/gpu-passthrough-tools.sh
Now, let's add our functions with clear documentation:
bash
#!/bin/bash
# GPU Passthrough Maintenance Tools
# Created: $(date +%Y-%m-%d)
# Purpose: Provide consistent tools for managing GPU passthrough configuration
# Configuration
LOG_FILE="/root/gpu-passthrough-config.log"
GRUB_CONFIG="/etc/default/grub"
# Log Update Function
# Records the current system state before updates
log_update() {
echo "=== Update Event $(date) ===" >> "$LOG_FILE"
echo "Previous kernel: $(uname -r)" >> "$LOG_FILE"
echo "Previous GRUB config:" >> "$LOG_FILE"
cat "$GRUB_CONFIG" >> "$LOG_FILE"
echo "Current IOMMU Groups:" >> "$LOG_FILE"
for i in /sys/kernel/iommu_groups/*; do
if [ -d "$i" ]; then
echo "Group ${i##*/}:" >> "$LOG_FILE"
ls -l "$i/devices/" >> "$LOG_FILE"
fi
done
echo "=== End Update Event ===" >> "$LOG_FILE"
echo "Logged current system state to $LOG_FILE"
}
# Backup Function
# Creates a dated backup of GRUB configuration
backup_grub() {
local backup_file="${GRUB_CONFIG}.backup.$(date +%Y%m%d)"
cp "$GRUB_CONFIG" "$backup_file"
echo "Created GRUB backup: $backup_file"
echo "=== GRUB Backup $(date) ===" >> "$LOG_FILE"
echo "Backup file created: $backup_file" >> "$LOG_FILE"
}
# Verification Function
# Checks current GPU passthrough configuration state
verify_passthrough() {
echo "=== Verification $(date) ===" >> "$LOG_FILE"
echo "Current kernel: $(uname -r)" >> "$LOG_FILE"
echo "Checking IOMMU status..."
echo "IOMMU Status:" >> "$LOG_FILE"
dmesg | grep -i "iommu" | tee -a "$LOG_FILE"
echo "Checking GPU status..."
echo "GPU Status:" >> "$LOG_FILE"
lspci -nnk -d 10de:2204 | tee -a "$LOG_FILE"
echo "Checking IOMMU grouping..."
echo "IOMMU Grouping:" >> "$LOG_FILE"
ls -l /sys/kernel/iommu_groups/13/devices/ | tee -a "$LOG_FILE"
echo "=== End Verification ===" >> "$LOG_FILE"
echo "Full verification results saved to $LOG_FILE"
}
# Make sure the log file exists
touch "$LOG_FILE"
echo "GPU Passthrough tools are ready to use."
echo "Log file location: $LOG_FILE"
Now, let's make the script executable and source it:
bash
chmod +x /root/gpu-passthrough-tools.sh
source /root/gpu-passthrough-tools.sh
After running these commands, the functions will be available in your current shell. You can now use them:
bash
log_update # Records current system state
backup_grub # Creates a GRUB configuration backup
verify_passthrough # Verifies GPU passthrough configuration
Each command will now provide feedback as it runs, and all information is logged to /root/gpu-passthrough-config.log for future reference.
5. System Update Procedures for GPU Passthrough
Let's now explore how to handle system updates while maintaining our GPU passthrough configuration. Think of this process like performing maintenance on a high-performance engine - we need to be methodical and careful to ensure everything continues running smoothly.
5.1 Before the Update
Before allowing any system update to proceed, we need to establish our current working state. This is similar to taking detailed photographs of a complex machine before disassembling it - we want to document exactly how everything was working. Let's use the tools we created earlier:
Document our pre-update state
log_update
Create a fresh backup of our GRUB configuration
backup_grub
Verify current functionality
verify_passthrough
This creates a comprehensive record of our working configuration. The log will contain entries showing our kernel version, GRUB configuration, and the state of our GPU passthrough setup. This information becomes invaluable if we need to troubleshoot issues after the update.
5.2 During the Update Process
When Proxmox presents system updates, pay special attention to entries that mention:
- Kernel updates (packages starting with
pve-kernel) - GRUB updates
- Firmware updates that might affect PCIe devices
As the update proceeds, watch the output carefully. You might see messages like:
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-6.8.12-8-pve
Found initrd image: /boot/initrd.img-6.8.12-8-pve
These messages indicate that GRUB is being updated. Don't worry - our configuration in /etc/default/grub should persist through this process because we're using the standard configuration file.
5.3 Immediate Post-Update Verification
Before rebooting into the new kernel, we should verify our configuration remains intact:
bash
# Compare current GRUB configuration with our backup
diff /etc/default/grub "/etc/default/grub.backup.$(date +%Y%m%d)"
If this command shows no differences in our GPU passthrough parameters, we can proceed with the reboot. If it does show differences, we need to restore our configuration:
bash
# Restore our known-good configuration
cp "/etc/default/grub.backup.$(date +%Y%m%d)" /etc/default/grub
update-grub
5.4 Post-Reboot Verification
After rebooting into the new kernel, we need to perform a complete verification of our GPU passthrough configuration. This is where our verification function becomes particularly valuable:
bash
# Run our comprehensive verification
verify_passthrough
Let's understand what each part of the verification tells us:
- When checking IOMMU status:
bash
dmesg | grep -i "iommu"
[ 0.053669] DMAR: IOMMU enabled
[ 2.785947] iommu: Default domain type: Passthrough
bashThis confirms our IOMMU parameters survived the update and are working correctly.
- When examining our GPU's status:
bash
lspci -nnk -d 10de:2204
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GA102 [GeForce RTX 3090] [10de:2204] (rev a1)
Subsystem: ASUSTeK Computer Inc. GA102 [GeForce RTX 3090] [1043:87d9]
Kernel modules: nvidiafb, nouveau
The absence of a "Kernel driver in use" line confirms our GPU remains unclaimed by host system drivers.
- Checking IOMMU grouping:
bash
ls -l /sys/kernel/iommu_groups/13/devices/
lrwxrwxrwx 1 root root 0 Feb 1 18:41 0000:01:00.0 -> ../../../../devices/pci0000:00/0000:00:01.0/0000:01:00.0
This verifies our GPU maintains its proper IOMMU group isolation.
5.5 Handling Verification Failures
If any of these verification steps show unexpected results, we have several options available to us. Think of this like having a series of fallback positions:
If the verification fails immediately after reboot:
# Restore our known-good configuration
cp "/etc/default/grub.backup.$(date +%Y%m%d)" /etc/default/grub
update-grub
reboot
If problems persist after restoration:
- Boot into the previous kernel from the GRUB menu
- Compare the kernel logs between working and non-working configurations
- Look for changes in how the new kernel handles our parameters
5.6 Troubleshooting Specific Verification Failures
Now that we have our tools properly set up, let's explore how to handle specific types of verification failures that might occur after system updates. Understanding these failures and their solutions helps us maintain a robust GPU passthrough setup over time.
IOMMU Verification Failures
When running verify_passthrough, you might encounter issues with IOMMU status. Let's look at different scenarios and their solutions:
Scenario 1: IOMMU Not Enabled If you see no IOMMU messages in the kernel log, or if you see something like:
bash[ 0.000000] DMAR: IOMMU disabled
This indicates our IOMMU parameters aren't being applied. Here's how to investigate and fix this:
bash
# First, check if our parameters are still present
cat /proc/cmdline
# If parameters are missing, verify our GRUB configuration
cat /etc/default/grub
# If needed, restore from our backup
backup_file=$(ls -t /etc/default/grub.backup.* | head -n1)
if [ -f "$backup_file" ]; then
cp "$backup_file" /etc/default/grub
update-grub
echo "Restored GRUB configuration from $backup_file"
fi
Scenario 2: Incorrect IOMMU Mode If you see:
bash[ 2.785947] iommu: Default domain type: Translated
Instead of "Passthrough", this means our iommu=pt parameter isn't being applied correctly. The system is using a different IOMMU mode that isn't optimal for GPU passthrough.
GPU Driver Binding Issues
Sometimes after updates, you might find that the host system has claimed our GPU. Here's how to investigate and resolve this:
bash
# Check current GPU status
lspci -nnk -d 10de:2204
If you see "kernel driver in use: nvidia" or "nouveau", we need to prevent this
To fix this, we create or modify the VFIO configuration:
bash
# Create a file to ensure VFIO claims our GPU
echo "options vfio-pci ids=10de:2204" > /etc/modprobe.d/vfio.conf
# Blacklist the NVIDIA and Nouveau drivers
cat << EOF > /etc/modprobe.d/blacklist-nvidia.conf
blacklist nvidia
blacklist nouveau
blacklist nvidiafb
EOF
# Update the initramfs to apply these changes
update-initramfs -u
IOMMU Group Changes
Sometimes updates can affect IOMMU grouping. If verify_passthrough shows our GPU has moved to a different IOMMU group or is suddenly grouped with other devices, we need to investigate the PCIe topology:
bash
# Check all IOMMU groups
for group in /sys/kernel/iommu_groups/*; do
if [ -d "$group" ]; then
echo "IOMMU Group ${group##*/}:"
ls -l "$group/devices/"
fi
done
This broader view helps us understand if the update has changed how the system organizes PCIe devices. If we see problems, we might need to:
- Try different PCIe slots for the GPU
- Adjust BIOS settings related to PCIe configuration
- Review our
pcie_acs_overrideparameter settings
Documenting Issues and Solutions
Whenever we encounter and solve an update-related issue, we should document it for future reference:
bash
# Add to our log file
echo "=== Issue Resolution $(date) ===" >> /root/gpu-passthrough-config.log
echo "Problem encountered: [describe the issue]" >> /root/gpu-passthrough-config.log
echo "Solution applied: [describe the fix]" >> /root/gpu-passthrough-config.log
This documentation becomes invaluable when similar issues arise in future updates.
5.7 Automating Verification and Troubleshooting
Just as modern cars have onboard diagnostic systems that continuously monitor engine performance, we can create automated checks for our GPU passthrough configuration. Let's develop a comprehensive monitoring system that helps us catch and address issues early.
Let's create a more sophisticated script that can run automatically during system updates or be executed manually when needed.
We'll call it gpu-passthrough-monitor.sh:
bash
nano /root/gpu-passthrough-monitor.sh
Here's our enhanced monitoring script:
bash
#!/bin/bash
# GPU Passthrough Monitoring System
# Purpose: Automatically verify GPU passthrough configuration and detect common issues
# Created: $(date +%Y-%m-%d)
# Configuration variables
LOG_FILE="/root/gpu-passthrough-config.log"
GRUB_CONFIG="/etc/default/grub"
GPU_ID="10de:2204" # RTX 3090 device ID
EXPECTED_IOMMU_GROUP="13" # Our GPU's expected IOMMU group
# Color coding for output readability
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
# Function to log and display messages
log_message() {
local message="$1"
local level="$2"
local color="$NC"
case "$level" in
"ERROR") color="$RED" ;;
"SUCCESS") color="$GREEN" ;;
"WARNING") color="$YELLOW" ;;
esac
echo -e "${color}${message}${NC}"
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $level: $message" >> "$LOG_FILE"
}
# Function to check GRUB parameters
check_grub_params() {
log_message "Checking GRUB parameters..." "INFO"
# Define required parameters
local required_params=("intel_iommu=on" "iommu=pt" "rd.driver.pre=vfio-pci"
"pcie_acs_override=downstream,multifunction")
# Read current cmdline
local cmdline=$(cat /proc/cmdline)
local missing_params=()
for param in "${required_params[@]}"; do
if ! echo "$cmdline" | grep -q "$param"; then
missing_params+=("$param")
fi
done
if [ ${#missing_params[@]} -eq 0 ]; then
log_message "All required GRUB parameters are present" "SUCCESS"
return 0
else
log_message "Missing GRUB parameters: ${missing_params[*]}" "ERROR"
return 1
fi
}
# Function to verify IOMMU status
check_iommu_status() {
log_message "Verifying IOMMU configuration..." "INFO"
# Check for IOMMU directories in sysfs
if [ -d "/sys/kernel/iommu_groups" ] && [ "$(ls -A /sys/kernel/iommu_groups)" ]; then
# Check if our specific IOMMU group exists and contains our GPU
if [ -d "/sys/kernel/iommu_groups/13" ]; then
log_message "IOMMU is active and properly configured" "SUCCESS"
return 0
fi
fi
# Additional verification through /proc/cmdline
if grep -q "intel_iommu=on" /proc/cmdline && grep -q "iommu=pt" /proc/cmdline; then
log_message "IOMMU parameters are active in kernel command line" "SUCCESS"
return 0
fi
log_message "IOMMU may not be properly enabled" "WARNING"
return 1
}
# Function to check GPU isolation
check_gpu_isolation() {
log_message "Checking GPU IOMMU grouping..." "INFO"
local gpu_group=$(readlink -f /sys/bus/pci/devices/0000:01:00.0/iommu_group)
if [ -d "$gpu_group" ]; then
local group_number=$(basename "$gpu_group")
local device_count=$(ls "$gpu_group/devices/" | wc -l)
if [ "$group_number" = "$EXPECTED_IOMMU_GROUP" ]; then
log_message "GPU is in the expected IOMMU group $EXPECTED_IOMMU_GROUP" "SUCCESS"
if [ "$device_count" -eq 1 ]; then
log_message "GPU is properly isolated in its IOMMU group" "SUCCESS"
return 0
else
log_message "GPU shares IOMMU group with other devices" "WARNING"
return 1
fi
else
log_message "GPU is in unexpected IOMMU group $group_number" "WARNING"
return 1
fi
else
log_message "Could not determine GPU IOMMU group" "ERROR"
return 2
fi
}
# Function to check driver binding
check_driver_binding() {
log_message "Checking GPU driver status..." "INFO"
local driver_info=$(lspci -nnk -d "$GPU_ID")
if echo "$driver_info" | grep -q "Kernel driver in use"; then
log_message "WARNING: GPU is claimed by a host system driver" "WARNING"
return 1
else
log_message "GPU is not bound to any host system driver" "SUCCESS"
return 0
fi
}
# Main execution function
main() {
log_message "Starting GPU passthrough verification" "INFO"
echo "----------------------------------------"
local has_errors=0
check_grub_params || has_errors=1
echo "----------------------------------------"
check_iommu_status || has_errors=1
echo "----------------------------------------"
check_gpu_isolation || has_errors=1
echo "----------------------------------------"
check_driver_binding || has_errors=1
echo "----------------------------------------"
if [ $has_errors -eq 0 ]; then
log_message "All checks passed successfully!" "SUCCESS"
else
log_message "Some checks failed - review the log for details" "WARNING"
fi
}
# Execute main function
main
5.8 Implementing Automated Update Checks
Now that we have our monitoring system in place, we can integrate it with Proxmox's update process to ensure our GPU passthrough configuration remains stable through system updates. Think of this like having an automatic safety system that checks everything before, during, and after any changes to our system.
Let's create an APT hook that will automatically run our checks during system updates. We'll place this in the APT directory where the package manager looks for scripts to run at specific times during the update process:
bash
nano /etc/apt/apt.conf.d/99gpu-passthrough-checks
In this file, we'll add the following configuration:
bash
# GPU Passthrough Update Checks
# Purpose: Automatically verify GPU passthrough configuration during system updates
# Pre-update checks (runs before the update begins)
DPkg::Pre-Invoke {
"/root/gpu-passthrough-tools.sh log_update";
"/root/gpu-passthrough-tools.sh backup_grub";
};
# Post-update checks (runs after the update completes but before reboot)
DPkg::Post-Invoke {
"/root/gpu-passthrough-monitor.sh > /root/gpu-passthrough-last-update.log 2>&1";
};
This configuration tells APT to run our verification tools at specific points during the update process. The Pre-Invoke section creates a snapshot of our working configuration before any changes occur, while the Post-Invoke section verifies everything is still correctly configured after the update.
Now let's ensure our monitoring script can handle being run automatically during updates. We'll modify our main monitoring script slightly to accommodate this use case:
bash
nano /root/gpu-passthrough-monitor.sh
Add this new function at the beginning of the script, just after our configuration variables:
bash
# Function to check if we're running during an update
check_update_context() {
if [ -f /var/lib/dpkg/lock ] || [ -f /var/lib/apt/lists/lock ]; then
# We're running during an update
export DURING_UPDATE=1
log_message "Running in update context" "INFO"
else
export DURING_UPDATE=0
log_message "Running in manual context" "INFO"
fi
}
# Modify our main() function to handle update context
main() {
check_update_context
log_message "Starting GPU passthrough verification" "INFO"
echo "----------------------------------------"
local has_errors=0
# Run our standard checks
check_grub_params || has_errors=1
echo "----------------------------------------"
check_iommu_status || has_errors=1
echo "----------------------------------------"
check_gpu_isolation || has_errors=1
echo "----------------------------------------"
check_driver_binding || has_errors=1
echo "----------------------------------------"
if [ $DURING_UPDATE -eq 1 ] && [ $has_errors -eq 1 ]; then
# We're during an update and found problems
log_message "WARNING: Issues detected during system update" "WARNING"
log_message "Review /root/gpu-passthrough-last-update.log after update completes" "WARNING"
# Create a visible warning file
echo "GPU Passthrough configuration issues detected during update on $(date)" \
> /root/GPU-PASSTHROUGH-WARNING.txt
elif [ $has_errors -eq 0 ]; then
log_message "All checks passed successfully!" "SUCCESS"
# Clean up warning file if it exists
rm -f /root/GPU-PASSTHROUGH-WARNING.txt
else
log_message "Some checks failed - review the log for details" "WARNING"
fi
}
Make sure the monitor is executable
bash
chmod +x /root/gpu-passthrough-monitor.sh
This enhanced version of our monitoring system does several important things:
- It recognizes whether it's running during a system update or manually
- It adjusts its behavior based on the context
- It creates highly visible warnings if issues are detected during updates
- It maintains detailed logs of all checks and their results
5.9 Testing and Notifications for Our Automated System
Having set up our automated monitoring system, we need to ensure it works reliably and effectively communicates any issues it finds. Think of this like testing a building's fire alarm system – we want to verify both that it detects problems and that it notifies us appropriately when they occur.
Testing Our Automated Checks
Let's create a safe way to test our monitoring system without actually disrupting our GPU passthrough configuration. We'll create a test script that simulates various scenarios our monitoring system should detect:
bashnano /root/gpu-passthrough-test.sh
Here's our testing script that safely simulates different failure conditions:
bash
#!/bin/bash
# GPU Passthrough Test Suite
# Purpose: Safely test our monitoring system's ability to detect configuration issues
# First, let's ensure we have a backup of our current configuration
if [ ! -f "/etc/default/grub.backup.$(date +%Y%m%d)" ]; then
echo "Creating backup before testing..."
/root/gpu-passthrough-tools.sh backup_grub
fi
# Function to restore our configuration after testing
cleanup() {
echo "Restoring original configuration..."
cp "/etc/default/grub.backup.$(date +%Y%m%d)" /etc/default/grub
update-grub
echo "Test cleanup complete"
}
# Set up our cleanup to run when the script exits
trap cleanup EXIT
# Test 1: Missing IOMMU Parameter
echo "Test 1: Simulating missing IOMMU parameter"
sed -i.test 's/intel_iommu=on/intel_iommu=skip/' /etc/default/grub
update-grub
/root/gpu-passthrough-monitor.sh
echo "Press Enter to continue to next test"
read
# Test 2: Incorrect IOMMU Mode
echo "Test 2: Simulating incorrect IOMMU mode"
sed -i.test 's/iommu=pt/iommu=translated/' /etc/default/grub
update-grub
/root/gpu-passthrough-monitor.sh
echo "Press Enter to continue to next test"
read
# Test 3: Missing VFIO Parameters
echo "Test 3: Simulating missing VFIO configuration"
sed -i.test 's/rd.driver.pre=vfio-pci//' /etc/default/grub
update-grub
/root/gpu-passthrough-monitor.sh
echo "Press Enter to finish testing"
read
This test script helps us verify that our monitoring system can detect various types of configuration issues. Each test simulates a different problem while ensuring we can safely restore our working configuration afterward.
Enhancing Notifications
Now let's add a more sophisticated notification system to alert us when issues are detected. We'll create a notification script that can use different methods to alert us:
bashnano /root/gpu-passthrough-notify.sh
Here's our notification system:
bash
#!/bin/bash
# GPU Passthrough Notification System
# Purpose: Provide clear notifications when configuration issues are detected
# Configuration variables
LOG_FILE="/root/gpu-passthrough-config.log"
NOTIFICATION_FILE="/root/GPU-PASSTHROUGH-WARNING.txt"
WARNING_LOG="/root/gpu-passthrough-last-update.log"
send_notification() {
local message="$1"
local severity="$2"
# First, log the notification
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $severity: $message" >> "$LOG_FILE"
# Create a visible warning file in /root
echo "GPU Passthrough Alert - $(date)" > "$NOTIFICATION_FILE"
echo "Severity: $severity" >> "$NOTIFICATION_FILE"
echo "Message: $message" >> "$NOTIFICATION_FILE"
echo "See $WARNING_LOG for details" >> "$NOTIFICATION_FILE"
# If we're in a GUI session, try to use notify-send
if [ -n "$DISPLAY" ]; then
notify-send -u critical "GPU Passthrough Alert" "$message"
fi
# If we have mail configured, send an email
if command -v mail >/dev/null 2>&1; then
echo "$message" | mail -s "GPU Passthrough Alert - $severity" root
fi
# Write to system journal for centralized logging
logger -t gpu-passthrough -p daemon.warning "$message"
}
# Function to format our warning log for easier reading
format_warning_log() {
if [ -f "$WARNING_LOG" ]; then
echo "GPU Passthrough Warning Summary" > "$NOTIFICATION_FILE"
echo "Generated: $(date)" >> "$NOTIFICATION_FILE"
echo "----------------------------------------" >> "$NOTIFICATION_FILE"
# Extract and format important messages from the warning log
grep -E "ERROR|WARNING|CRITICAL" "$WARNING_LOG" | \
sed 's/^/ /' >> "$NOTIFICATION_FILE"
echo "----------------------------------------" >> "$NOTIFICATION_FILE"
echo "Full details available in $WARNING_LOG" >> "$NOTIFICATION_FILE"
fi
}
# Main notification handler
handle_notification() {
local severity="$1"
local message="$2"
case "$severity" in
"ERROR")
send_notification "$message" "ERROR"
format_warning_log
;;
"WARNING")
send_notification "$message" "WARNING"
format_warning_log
;;
*)
echo "Unknown severity level: $severity"
return 1
;;
esac
}
# If this script is being run directly, show usage
if [[ "${BASH_SOURCE[0]}" == "${0}" ]]; then
echo "Usage: $0 is meant to be sourced by gpu-passthrough-monitor.sh"
echo "Direct usage: $0 <severity> <message>"
echo "Example: $0 WARNING 'IOMMU configuration issue detected'"
fi
5.10 Integrating Notifications with System Monitoring
Now that we have both our monitoring and notification systems, let's bring them together to create a comprehensive system that actively watches over our GPU passthrough configuration. Think of this integration like connecting a home security system to a monitoring service – we want our detection system to effectively communicate any issues it finds.
First, let's modify our main monitoring script to use our new notification system. We'll update /root/gpu-passthrough-monitor.sh to integrate the notifications:
bash
#!/bin/bash
# Source our notification system
source /root/gpu-passthrough-notify.sh
# Previous configuration variables remain the same...
# Enhance our log_message function to use the notification system
log_message() {
local message="$1"
local level="$2"
local notify="$3" # New parameter to control notifications
# Original logging code remains...
# If this is a warning or error and notifications are requested
if [ "$notify" = "yes" ] && [ "$level" != "INFO" ] && [ "$level" != "SUCCESS" ]; then
handle_notification "$level" "$message"
fi
}
# Update our check functions to trigger notifications for important issues
check_grub_params() {
log_message "Checking GRUB parameters..." "INFO" "no"
# Previous check code remains...
if [ ${#missing_params[@]} -eq 0 ]; then
log_message "All required GRUB parameters are present" "SUCCESS" "no"
return 0
else
log_message "Missing GRUB parameters: ${missing_params[*]}" "ERROR" "yes"
return 1
fi
}
# Similarly update other check functions...
Remember, after each log_message, there needs to be a "yes" for notify or "no" to no notification after our altered code.
Now let's create a regular monitoring service that will run these checks periodically. We'll use systemd for this purpose:
bashnano /etc/systemd/system/gpu-passthrough-monitor.service
Here's our service definition:
ini
[Unit]
Description=GPU Passthrough Configuration Monitor
After=network.target
StartLimitIntervalSec=0
[Service]
Type=oneshot
ExecStart=/root/gpu-passthrough-monitor.sh
StandardOutput=append:/var/log/gpu-passthrough-monitor.log
StandardError=append:/var/log/gpu-passthrough-monitor.log
RemainAfterExit=yes
TimeoutSec=300
[Install]
WantedBy=multi-user.target
StartLimitIntervalSec=0prevents the service from being rate-limitedStandardOutputandStandardErrorensure we capture all output in a dedicated log fileRemainAfterExit=yeshelps with service status trackingTimeoutSec=300gives the script plenty of time to complete its checks
And create a timer to run our checks regularly:
bash
nano /etc/systemd/system/gpu-passthrough-monitor.timer
ini
[Unit]
Description=Regular GPU Passthrough Configuration Checks
Requires=gpu-passthrough-monitor.service
[Timer]
OnBootSec=5min
OnUnitActiveSec=1h
RandomizedDelaySec=60
AccuracySec=1min
Persistent=true
[Install]
WantedBy=timers.target
Requiresensures the service unit is availableRandomizedDelaySecprevents all timers from running at exactly the same timePersistent=trueensures missed runs will be executed when possible
This setup will check our configuration an hour after booting and then every hour afterward. The AccuracySec parameter ensures our checks don't drift over time.
Let's enable and start our monitoring service:
bash
systemctl daemon-reload
systemctl enable gpu-passthrough-monitor.timer
systemctl start gpu-passthrough-monitor.timer
We can verify it's working:
bashsystemctl status gpu-passthrough-monitor.timer
Now, when our monitoring system detects an issue, it will:
- Log the issue in detail
- Create visible warning files when appropriate
- Send system notifications if we're in a GUI session
- Write to the system journal for centralized logging
- Attempt to send email notifications if mail is configured
The system runs these checks:
- During system updates (through our APT hooks)
- Hourly (through our systemd timer)
- After every boot (also through our timer)
- Whenever we run the monitoring script manually
This comprehensive monitoring helps ensure we catch any issues with our GPU passthrough configuration early, whether they occur during system updates or arise through other changes to the system.
Recapping the scripts we have made so far to automate:
gpu-passthrough-tools.shThis was our first script, created to provide basic management functions like:
- Creating backups of GRUB configurations
- Logging system states
- Basic verification functions We created this early in the process to handle routine tasks.
gpu-passthrough-monitor.shThis is our main monitoring script that handles:
- Checking GRUB parameters
- Verifying IOMMU configuration
- Checking GPU isolation
- Monitoring driver bindings This script is designed to run both manually and through our systemd service.
gpu-passthrough-notify.shThis script handles notifications when issues are detected, including:
- Creating visible warning files
- Sending system notifications
- Writing to system logs
- Attempting email notifications if configured
gpu-passthrough-test.shThis is our testing script that helps verify our monitoring system by:
- Simulating various failure conditions
- Testing our notification system
- Verifying our recovery procedures
- Ensuring our backups work correctly
5.11 Customizing Monitoring Frequency and Thresholds
While our monitoring system provides a solid foundation for maintaining GPU passthrough configuration, we might want to adjust how frequently it checks our system and what conditions trigger alerts. Think of this like fine-tuning a security system to match your specific needs – we want enough monitoring to catch problems early without generating unnecessary alerts.
Adjusting Check Frequency
Our current setup runs checks hourly and after system boots, but you might want to customize this based on your system's usage patterns. Let's modify our timer configuration to better match your needs:
bashnano /etc/systemd/system/gpu-passthrough-monitor.timer
For a system that undergoes frequent changes, you might want more frequent checks. For example, to check every 15 minutes instead of hourly or you might want to increase the time between checks, this is completely up to you:
ini
[Unit]
Description=Regular GPU Passthrough Configuration Checks
[Timer]
OnBootSec=5min
OnUnitActiveSec=15min
RandomizedDelaySec=60
AccuracySec=1min
Persistent=true
[Install]
WantedBy=timers.target
The OnUnitActiveSec=15min parameter tells systemd to run our checks every 15 minutes. The RandomizedDelaySec=60parameter helps prevent resource contention by adding a small random delay to each check.
Enhancing Check Sensitivity
Our monitoring system currently looks for specific conditions that might affect GPU passthrough. We can enhance this by adding checks for related system states that could impact performance or stability. Let's add these to our monitoring script:
bashnano /root/gpu-passthrough-monitor.sh
We'll add a new function to check for optimal performance conditions:
check_performance_conditions() {
log_message "Checking system performance conditions..." "INFO" "no"
# Check CPU virtualization features
if ! grep -q -E "vmx|svm" /proc/cpuinfo; then
log_message "CPU virtualization features may not be enabled in BIOS" "WARNING" "yes"
return 1
fi
# Check memory allocation
total_mem=$(grep MemTotal /proc/meminfo | awk '{print $2}')
if [ "$total_mem" -lt 8388608 ]; then # Less than 8GB in KB
log_message "System memory might be insufficient for optimal performance" "WARNING" "yes"
return 1
fi
# Check power management settings
if [ -f "/sys/module/intel_iommu/parameters/strict" ]; then
if [ "$(cat /sys/module/intel_iommu/parameters/strict)" != "1" ]; then
log_message "IOMMU strict mode is not enabled" "INFO" "yes"
fi
fi
# Check PCIe link status for GPU
if [ -f "/sys/bus/pci/devices/0000:01:00.0/current_link_speed" ]; then
link_speed=$(cat /sys/bus/pci/devices/0000:01:00.0/current_link_speed)
if [[ "$link_speed" != *"16.0 GT/s"* ]]; then
log_message "GPU PCIe link not running at optimal speed" "WARNING" "yes"
return 1
fi
fi
log_message "Performance conditions check passed" "SUCCESS" "no"
return 0
}Dont forget to add the following lines to the main execution function
check_performance_conditions || has_errors=1
echo "----------------------------------------"
This new function helps us monitor not just the basic configuration but also the conditions that affect GPU passthrough performance. The checks examine CPU virtualization features, system memory availability, IOMMU optimization settings, and PCIe link status.
5.12 Integrating Enhanced Performance Monitoring
Now that we've added performance condition checks to our monitoring system, let's integrate these deeper insights into our overall monitoring approach. Just as a skilled mechanic doesn't just check if an engine runs but also monitors its efficiency and performance characteristics, our enhanced monitoring provides a more complete picture of our GPU passthrough system's health.
Let's modify our main monitoring workflow to incorporate these new checks. We'll update the main execution function in our monitoring script:
bashnano /root/gpu-passthrough-monitor.sh
In the script, we'll enhance the main function to include our new performance monitoring:
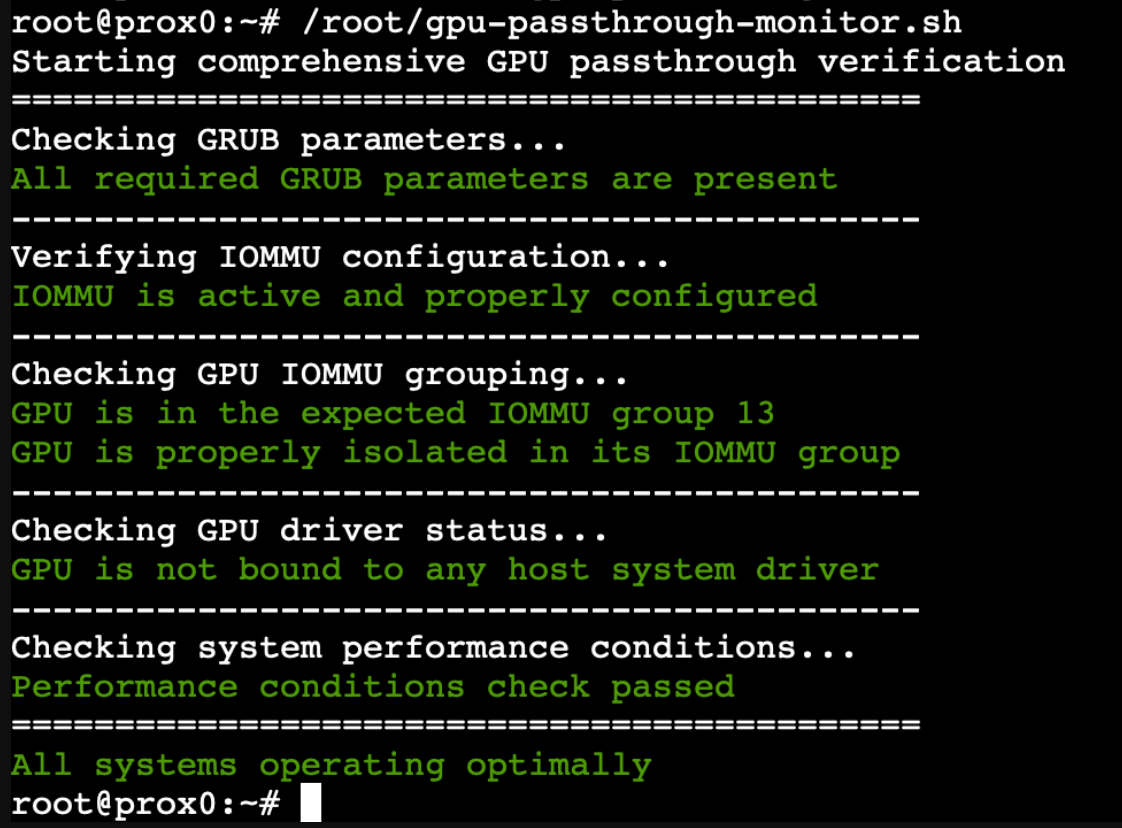
# Main execution function
main() {
local has_errors=0
local has_warnings=0
log_message "Starting comprehensive GPU passthrough verification" "INFO" "no"
echo "============================================"
# First, check our basic configuration
check_grub_params || has_errors=1
echo "--------------------------------------------"
# Check IOMMU configuration and isolation
check_iommu_status || has_errors=1
echo "--------------------------------------------"
# Verify GPU isolation
check_gpu_isolation || has_errors=1
echo "--------------------------------------------"
# Check driver binding
check_driver_binding || has_errors=1
echo "--------------------------------------------"
# Now include our performance condition checks
check_performance_conditions || has_warnings=1
echo "============================================"
# Provide a detailed summary based on all checks
if [ $has_errors -eq 0 ] && [ $has_warnings -eq 0 ]; then
log_message "All systems operating optimally" "SUCCESS" "no"
elif [ $has_errors -eq 0 ] && [ $has_warnings -eq 1 ]; then
log_message "Configuration is functional but performance could be improved" "WARNING" "yes"
echo "Review the logs for optimization opportunities"
else
log_message "Critical issues detected in configuration" "ERROR" "yes"
echo "Review logs immediately and address configuration issues"
fi # Provide a detailed summary based on all checks
if [ $has_errors -eq 0 ] && [ $has_warnings -eq 0 ]; then
log_message "All systems operating optimally" "SUCCESS" "no"
elif [ $has_errors -eq 0 ] && [ $has_warnings -eq 1 ]; then
log_message "Configuration is functional but performance could be improved" "WARNING" "yes"
echo "Review the logs for optimization opportunities"
else
log_message "Critical issues detected in configuration" "ERROR" "yes"
echo "Review logs immediately and address configuration issues"
fi
# Record check results for trend analysis
record_check_results $has_errors $has_warnings
}
# Add a new function to track check results over time
record_check_results() {
local errors=$1
local warnings=$2
local timestamp=$(date '+%Y-%m-%d %H:%M:%S')
echo "$timestamp,$errors,$warnings" >> "/root/gpu-passthrough-trends.csv"
# Keep only the last 30 days of data
if [ -f "/root/gpu-passthrough-trends.csv" ]; then
tail -n 720 "/root/gpu-passthrough-trends.csv" > "/root/gpu-passthrough-trends.tmp"
mv "/root/gpu-passthrough-trends.tmp" "/root/gpu-passthrough-trends.csv"
fi
}
# Execute main function
mainThis enhanced monitoring approach provides several benefits:
- It distinguishes between critical configuration issues and performance optimization opportunities
- It maintains a history of check results, allowing us to spot trends over time
- It provides clear, actionable feedback about the state of our system
- It automatically manages the size of our trend data to prevent unlimited growth
The trend data can be particularly valuable for understanding how system updates and changes affect our GPU passthrough configuration over time. By keeping this historical record, we can better understand the impact of system changes and identify patterns that might need attention.
5.13 Analyzing and Interpreting Performance Trends
Understanding trends in your GPU passthrough configuration helps identify patterns that might affect system stability and performance. Think of this like a doctor reviewing your health records over time – individual readings tell you about the current state, but trends reveal the bigger picture of system health.
Understanding the Trend Data
Our monitoring system creates a CSV file at /root/gpu-passthrough-trends.csv that contains three key pieces of information for each check:
- Timestamp: When the check occurred
- Error count: Number of critical configuration issues
- Warning count: Number of performance-related concerns
Let's create a simple analysis script to help us interpret this data.
nano /root/gpu-passthrough-analyze.sh
bash
#!/bin/bash
# GPU Passthrough Trend Analysis
# Purpose: Analyze historical monitoring data to identify patterns and potential issues
# Configuration
TREND_FILE="/root/gpu-passthrough-trends.csv"
LOG_FILE="/root/gpu-passthrough-config.log"
analyze_trends() {
echo "GPU Passthrough Configuration Analysis"
echo "======================================"
# First, let's look at our recent history
echo "Recent Configuration Status:"
echo "----------------------------"
# Check the last 24 hours of data
local recent_errors=$(tail -n 24 "$TREND_FILE" | grep -c ",1,")
local recent_warnings=$(tail -n 24 "$TREND_FILE" | grep -c ",[0-9]*,1")
echo "Last 24 hours:"
echo " Critical Issues: $recent_errors"
echo " Performance Warnings: $recent_warnings"
# Look for patterns in the data
if [ $recent_errors -gt 0 ]; then
echo -e "\nConfiguration Issue Pattern Analysis:"
echo "--------------------------------"
# Extract timestamps of errors for pattern analysis
grep ",1," "$TREND_FILE" | tail -n 5 | while read -r line; do
timestamp=$(echo "$line" | cut -d',' -f1)
echo " Issue detected at: $timestamp"
# Pull relevant log entries
grep -B 2 -A 2 "$timestamp" "$LOG_FILE"
done
fi
# Analyze performance trends
echo -e "\nPerformance Trend Analysis:"
echo "-------------------------"
# Calculate the percentage of checks with warnings
total_checks=$(wc -l < "$TREND_FILE")
warning_percentage=$(bc <<< "scale=2; $recent_warnings * 100 / 24")
echo "Performance warning rate: ${warning_percentage}%"
# Provide contextual analysis
if (( $(echo "$warning_percentage > 20" | bc -l) )); then
echo "Note: Higher than normal warning rate detected."
echo "Consider reviewing system configuration for optimization opportunities."
# Extract specific warning patterns
echo -e "\nMost common warning types:"
grep "WARNING" "$LOG_FILE" | tail -n 50 | sort | uniq -c | sort -nr | head -n 3
fi
}
# Generate a simple report
generate_report() {
local report_file="/root/gpu-passthrough-report-$(date +%Y%m%d).txt"
{
echo "GPU Passthrough Status Report"
echo "Generated: $(date)"
echo "==============================="
echo
analyze_trends
echo -e "\nSystem Information:"
echo "-------------------"
echo "Kernel: $(uname -r)"
echo "IOMMU Groups:"
find /sys/kernel/iommu_groups/ -type l | sort -V
echo -e "\nCurrent GPU Status:"
lspci -nnk -d 10de:2204
} > "$report_file"
echo "Report generated: $report_file"
}
# Execute the analysis
analyze_trends
echo -e "\nWould you like to generate a full report? (y/n)"
read -r response
if [[ "$response" =~ ^[Yy]$ ]]; then
generate_report
fi
This analysis script helps us understand the historical performance of our GPU passthrough configuration by:
- Identifying patterns in configuration issues
- Tracking the frequency of performance warnings
- Correlating issues with system events
- Providing actionable insights based on the data
5.14 Automated Reporting and Notifications
Having data about our system's performance is valuable, but the real power comes from automatically analyzing this information and presenting it in a way that helps us make informed decisions. Think of this like having a skilled system administrator who regularly reviews your logs and provides you with clear, actionable summaries.
Let's create a comprehensive reporting system that will automatically generate and deliver periodic status reports. We'll create a new script called
/root/gpu-passthrough-report.sh
bash
#!/bin/bash
# GPU Passthrough Automated Reporting System
# Purpose: Generate and deliver regular status reports about GPU passthrough health
# Our script starts by defining the locations of our important files
REPORT_DIR="/root/gpu-passthrough-reports"
TREND_FILE="/root/gpu-passthrough-trends.csv"
LOG_FILE="/root/gpu-passthrough-config.log"
CURRENT_DATE=$(date +%Y%m%d)
# First, ensure our report directory exists
mkdir -p "$REPORT_DIR"
# This function creates a detailed performance analysis
generate_performance_analysis() {
local report_file="$1"
{
echo "Performance Analysis Report"
echo "=========================="
echo "Generated on: $(date)"
echo
echo "System Information"
echo "-----------------"
echo "Kernel Version: $(uname -r)"
echo "Uptime: $(uptime)"
echo
echo "GPU Passthrough Configuration Status"
echo "----------------------------------"
# Check current GRUB parameters
echo "Active GRUB Parameters:"
grep -E "intel_iommu|iommu|vfio" /proc/cmdline
echo
# IOMMU Group Information
echo "Current IOMMU Grouping:"
ls -l /sys/kernel/iommu_groups/13/devices/
echo
# GPU Status
echo "GPU Status:"
lspci -nnk -d 10de:2204
echo
echo "Performance Metrics"
echo "------------------"
# Calculate stability metrics from our trend data
total_checks=$(wc -l < "$TREND_FILE")
error_count=$(grep -c ",1," "$TREND_FILE")
warning_count=$(grep -c ",[0-9]*,1" "$TREND_FILE")
echo "Last 24 Hours:"
echo "- Total Checks: $total_checks"
echo "- Configuration Errors: $error_count"
echo "- Performance Warnings: $warning_count"
echo "- Stability Rate: $(bc <<< "scale=2; 100 - ($error_count * 100 / $total_checks)")%"
echo
echo "Recent Events"
echo "-------------"
# Show the last 5 significant events from our logs
echo "Last 5 significant events:"
grep -E "ERROR|WARNING" "$LOG_FILE" | tail -n 5
} > "$report_file"
}
# This function creates a more concise summary for email notifications
generate_email_summary() {
local summary_file="$1"
{
echo "GPU Passthrough Status Summary"
echo "=============================="
echo
# Quick status check
if /root/gpu-passthrough-monitor.sh > /dev/null 2>&1; then
echo "Current Status: HEALTHY"
else
echo "Current Status: ATTENTION NEEDED"
fi
echo
# Add key metrics
echo "Key Metrics (Last 24 Hours):"
echo "- Configuration Status: $(tail -n 1 "$TREND_FILE" | cut -d',' -f2)"
echo "- Performance Status: $(tail -n 1 "$TREND_FILE" | cut -d',' -f3)"
echo
echo "Full report available at: $REPORT_DIR/report-$CURRENT_DATE.txt"
} > "$summary_file"
}
# Main execution
main() {
# Generate the full report
local report_file="$REPORT_DIR/report-$CURRENT_DATE.txt"
generate_performance_analysis "$report_file"
# Generate email summary
local summary_file="$REPORT_DIR/summary-$CURRENT_DATE.txt"
generate_email_summary "$summary_file"
# If mail is configured, send the summary
if command -v mail > /dev/null 2>&1; then
cat "$summary_file" | mail -s "GPU Passthrough Status Report - $CURRENT_DATE" root
fi
# Maintain report history (keep last 30 days)
find "$REPORT_DIR" -name "report-*.txt" -mtime +30 -delete
find "$REPORT_DIR" -name "summary-*.txt" -mtime +30 -delete
}
# Execute our main function
main
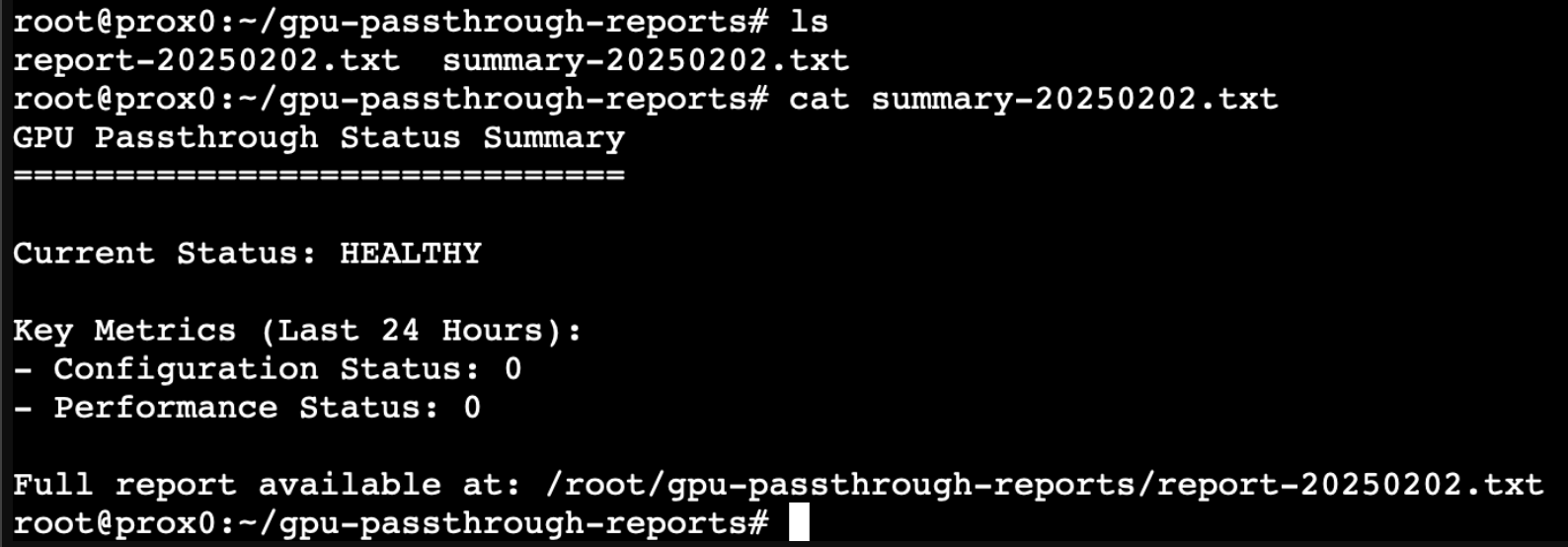

Now let's create a systemd timer to run our reports regularly:
bash
nano /etc/systemd/system/gpu-passthrough-report.timer
ini
[Unit]
Description=GPU Passthrough Daily Report Generator
[Timer]
OnCalendar=daily
Persistent=true
RandomizedDelaySec=3600
[Install]
WantedBy=timers.target
And its corresponding service:
bashnano /etc/systemd/system/gpu-passthrough-report.service
ini
[Unit]
Description=GPU Passthrough Report Generation Service
After=network.target
[Service]
Type=oneshot
ExecStart=/root/gpu-passthrough-report.sh
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.target
5.15 Understanding and Customizing Report Thresholds
The automated reports we've set up provide valuable insights into our GPU passthrough system's health, but to make the most of this information, we need to understand what the different metrics mean and how to adjust the thresholds to match our specific needs. Think of this like calibrating a diagnostic tool – we need to understand what "normal" looks like for our particular setup.
Let's create a configuration file that will allow us to customize our monitoring thresholds. This will help us define what constitutes a warning versus an error condition for our specific use case:
bash
nano /root/gpu-passthrough-config.conf
bash
# GPU Passthrough Configuration Thresholds
# Purpose: Define custom alert thresholds for monitoring system
# Performance Warning Thresholds
# Percentage of checks that can show warnings before alerting
MAX_WARNING_PERCENTAGE=20
# Error Tolerance Settings
# Number of errors within 24 hours before triggering critical alert
MAX_DAILY_ERRORS=3
# IOMMU Group Monitoring
# Expected IOMMU group for our GPU
EXPECTED_IOMMU_GROUP=13
# PCIe Performance Settings
# Minimum acceptable PCIe link speed for optimal performance
MIN_PCIE_SPEED="16.0 GT/s"
# System Resource Thresholds
# Minimum system memory in GB for optimal performance
MIN_SYSTEM_MEMORY=16
# Alert Notification Settings
# Time in minutes to wait between repeated alerts
ALERT_COOLDOWN=60
# Report Generation Settings
# Number of days to keep historical reports
REPORT_RETENTION_DAYS=30
Now let's create a script that will help us understand and adjust these thresholds based on our system's behavior. We'll call this /root/gpu-passthrough-tune.sh:
bash
#!/bin/bash
# GPU Passthrough Threshold Tuning Tool
# Purpose: Help analyze and adjust monitoring thresholds based on system behavior
source /root/gpu-passthrough-config.conf
analyze_historical_performance() {
echo "Analyzing System Performance History"
echo "=================================="
echo
# Calculate average warning rate over the past week
local total_warnings=0
local total_checks=0
while IFS=, read -r timestamp errors warnings; do
((total_checks++))
if [ "$warnings" -eq 1 ]; then
((total_warnings++))
fi
done < <(tail -n 168 "/root/gpu-passthrough-trends.csv") # Last 7 days (24*7=168 hours)
local current_warning_rate=$(bc <<< "scale=2; $total_warnings * 100 / $total_checks")
echo "Current Performance Metrics:"
echo "--------------------------"
echo "Warning Rate: ${current_warning_rate}%"
echo "Configured Threshold: ${MAX_WARNING_PERCENTAGE}%"
echo
# Provide threshold recommendations
if (( $(echo "$current_warning_rate > $MAX_WARNING_PERCENTAGE" | bc -l) )); then
echo "Current warning rate exceeds threshold."
echo "Consider investigating frequent warnings or adjusting threshold."
# Analyze warning patterns
echo
echo "Most Common Warnings:"
grep "WARNING" /root/gpu-passthrough-config.log |
tail -n 100 | sort | uniq -c | sort -nr | head -n 3
else
echo "Warning rate is within acceptable range."
fi
}
suggest_thresholds() {
echo
echo "Threshold Recommendations"
echo "========================"
# Analyze PCIe performance
local current_speed=$(cat /sys/bus/pci/devices/0000:01:00.0/current_link_speed)
echo "PCIe Link Speed Analysis:"
echo "Current: $current_speed"
echo "Minimum: $MIN_PCIE_SPEED"
if [[ "$current_speed" != "$MIN_PCIE_SPEED" ]]; then
echo "Consider adjusting MIN_PCIE_SPEED to match current stable performance"
echo "Suggested: MIN_PCIE_SPEED=\"$current_speed\""
fi
# Analyze system memory
local total_mem=$(($(grep MemTotal /proc/meminfo | awk '{print $2}') / 1024 / 1024))
echo
echo "System Memory Analysis:"
echo "Current: ${total_mem}GB"
echo "Minimum: ${MIN_SYSTEM_MEMORY}GB"
if [ "$total_mem" -lt "$MIN_SYSTEM_MEMORY" ]; then
echo "Warning: Current system memory is below recommended minimum"
fi
}
apply_suggestions() {
local config_file="/root/gpu-passthrough-config.conf"
local timestamp=$(date +%Y%m%d-%H%M%S)
# Backup current configuration
cp "$config_file" "${config_file}.backup-${timestamp}"
echo
echo "Would you like to:"
echo "1. Adjust warning threshold"
echo "2. Update PCIe speed threshold"
echo "3. Modify system memory threshold"
echo "4. Exit without changes"
read -p "Enter your choice (1-4): " choice
case $choice in
1)
read -p "Enter new warning percentage threshold (current: $MAX_WARNING_PERCENTAGE): " new_threshold
sed -i "s/MAX_WARNING_PERCENTAGE=.*/MAX_WARNING_PERCENTAGE=$new_threshold/" "$config_file"
;;
2)
read -p "Enter new PCIe speed threshold: " new_speed
sed -i "s/MIN_PCIE_SPEED=.*/MIN_PCIE_SPEED=\"$new_speed\"/" "$config_file"
;;
3)
read -p "Enter new minimum memory threshold in GB: " new_mem
sed -i "s/MIN_SYSTEM_MEMORY=.*/MIN_SYSTEM_MEMORY=$new_mem/" "$config_file"
;;
4)
echo "No changes made"
return
;;
esac
echo "Configuration updated. New settings will take effect on next monitoring cycle."
}
# Main execution
echo "GPU Passthrough Threshold Tuning Utility"
echo "======================================"
echo
analyze_historical_performance
suggest_thresholds
echo
read -p "Would you like to adjust any thresholds? (y/n): " response
if [[ "$response" =~ ^[Yy]$ ]]; then
apply_suggestions
fi
5.16 Interpreting and Acting on System Recommendations
Now that we have our monitoring and tuning systems in place, let's understand how to interpret the data they provide and make informed decisions about our GPU passthrough configuration. Think of this like learning to read the diagnostic results from a sophisticated medical test – the data is valuable, but knowing how to interpret it makes it actionable.
Understanding Warning Patterns
Our monitoring system tracks several key metrics. Let's examine what each type of warning means and how to respond:
When you see warnings about PCIe link speed, this indicates that your GPU isn't operating at its full potential. For our RTX 3090, we expect to see a link speed of 16.0 GT/s. If you see a lower speed, this might indicate:
- A suboptimal PCIe slot configuration
- Power management settings affecting performance
- Physical installation issues
- BIOS settings that need adjustment
For example, if our tuning tool reports:
PCIe Link Speed Analysis:
Current: 8.0 GT/s
Minimum: 16.0 GT/s
This suggests we should investigate:
- Whether the GPU is installed in the primary PCIe x16 slot
- BIOS settings related to PCIe link speed
- Power management settings that might be downclocking the PCIe bus
Memory Usage Patterns
Our monitoring includes checks for system memory availability. For a system running GPU passthrough with an RTX 3090, we recommend at least 16GB of system memory. When our tool reports:
System Memory Analysis:
Current: 12GB
Minimum: 16GB
This indicates potential resource constraints that could affect performance. The warning exists because:
- The host system needs memory for its operations
- The virtual machine needs dedicated memory allocation
- The RTX 3090's significant memory capacity (24GB) suggests memory-intensive workloads
- System stability requires adequate memory headroom
IOMMU Group Stability
One of the most critical aspects our monitoring tracks is IOMMU group stability. When our tool reports changes in IOMMU grouping, this deserves immediate attention. For example, if we see:
IOMMU Group Analysis:
Expected Group: 13
Current Group: 14
This unexpected change could indicate:
- A system update has modified IOMMU behavior
- Changes in BIOS settings
- Hardware configuration changes
- Kernel parameter changes
Using the Tuning Tool Effectively
The tuning tool we've created helps identify optimal thresholds for your specific setup. Here's how to use it effectively:
- First, establish a baseline during normal operation:
bash/root/gpu-passthrough-tune.sh
- Review the initial analysis:
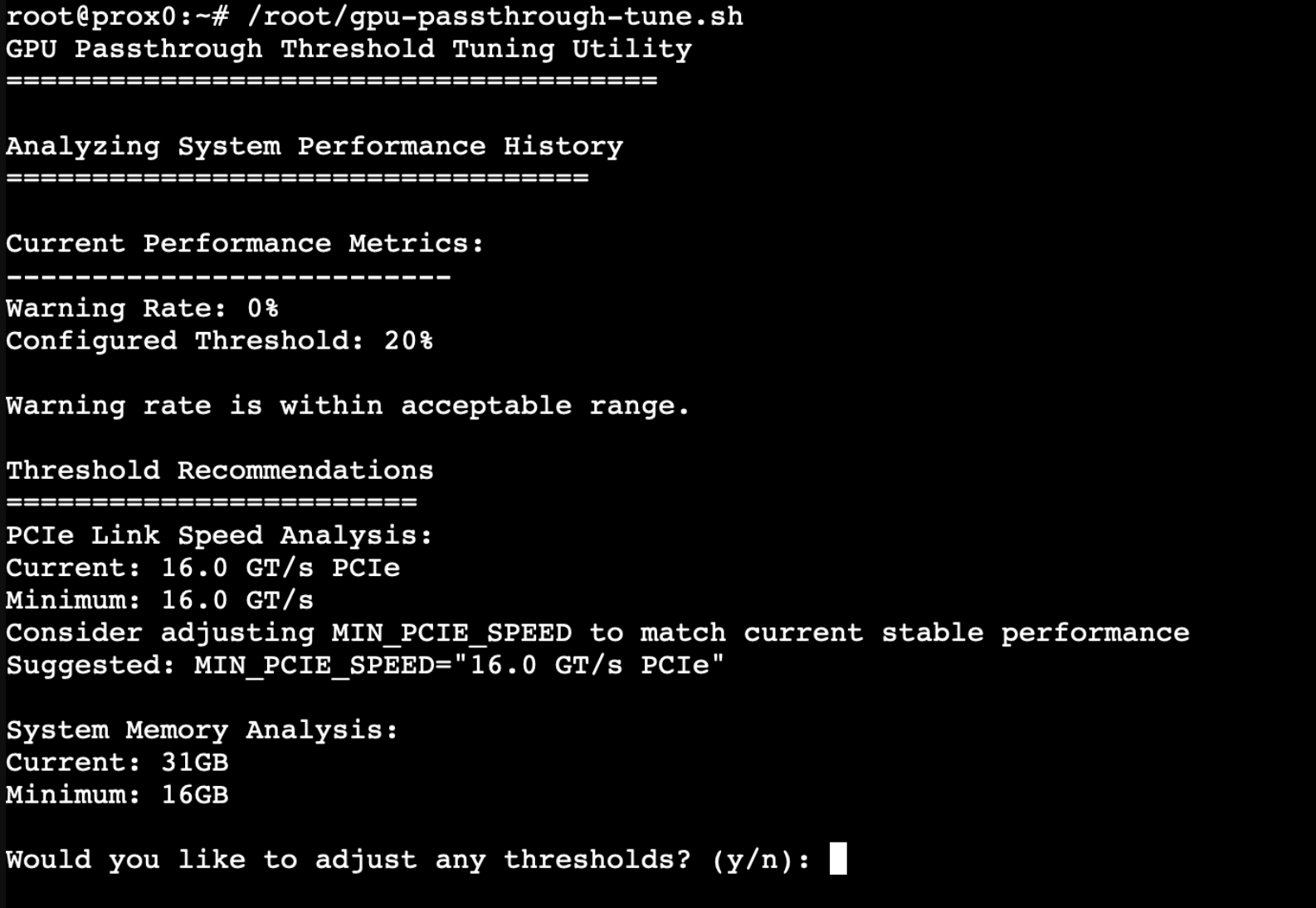
- Consider adjusting thresholds if:
- You see consistent warnings that don't affect your actual usage
- You need stricter monitoring for critical workloads
- Your system's normal operating conditions differ from defaults
- When making adjustments, follow this process:
- Document current performance and stability
- Make small, incremental changes
- Monitor the system for at least 24 hours after changes
- Document any positive or negative effects
6. Conclusion: Maintaining a Robust GPU Passthrough Configuration
Throughout this guide, we've explored the intricate process of managing and maintaining GPU passthrough configurations in Proxmox VE, with a particular focus on the GRUB parameters that form the foundation of this setup. Just as a well-maintained engine requires regular attention and care, a GPU passthrough configuration needs systematic monitoring and maintenance to perform optimally.
We began by understanding the crucial role GRUB parameters play in establishing the necessary environment for GPU passthrough. These parameters aren't just configuration options; they're the fundamental instructions that tell our system how to handle hardware isolation and resource management from the very moment it starts up.
Our journey then took us through the creation of a comprehensive monitoring system. We developed tools that not only watch for potential issues but help us understand the deeper patterns in our system's behavior. This monitoring system serves as our early warning system, alerting us to potential problems before they can impact system stability or performance.
The automated reporting system we established provides regular insights into our system's health, while our tuning tools help us maintain optimal performance by adjusting thresholds based on real-world usage patterns. This combination of monitoring, reporting, and tuning creates a feedback loop that helps our GPU passthrough configuration evolve and improve over time.
Perhaps most importantly, we've built a resilient update management system that helps protect our GPU passthrough configuration during system updates. By implementing proper backup procedures and verification steps, we've created a safety net that allows us to confidently update our system while maintaining the stability of our GPU passthrough setup.
Remember that maintaining a GPU passthrough configuration is an ongoing process. Regular monitoring, timely adjustments, and systematic update management are key to ensuring long-term stability and performance. The tools and procedures we've established provide a framework for this maintenance, but they should be adapted and refined based on your specific needs and experiences.
By following these practices and utilizing the tools we've created, you can maintain a robust and reliable GPU passthrough configuration that continues to perform optimally, even as your system evolves through updates and changes.

